Historical context
In testing CRAM 3.0, 3.1 (and 4.0) compression codecs I was reminded of a chart I made on the results of the SequenceSqueeze competition for the Fqzcomp/Fastqz paper. The source pic is there, but I embed an annotated copy
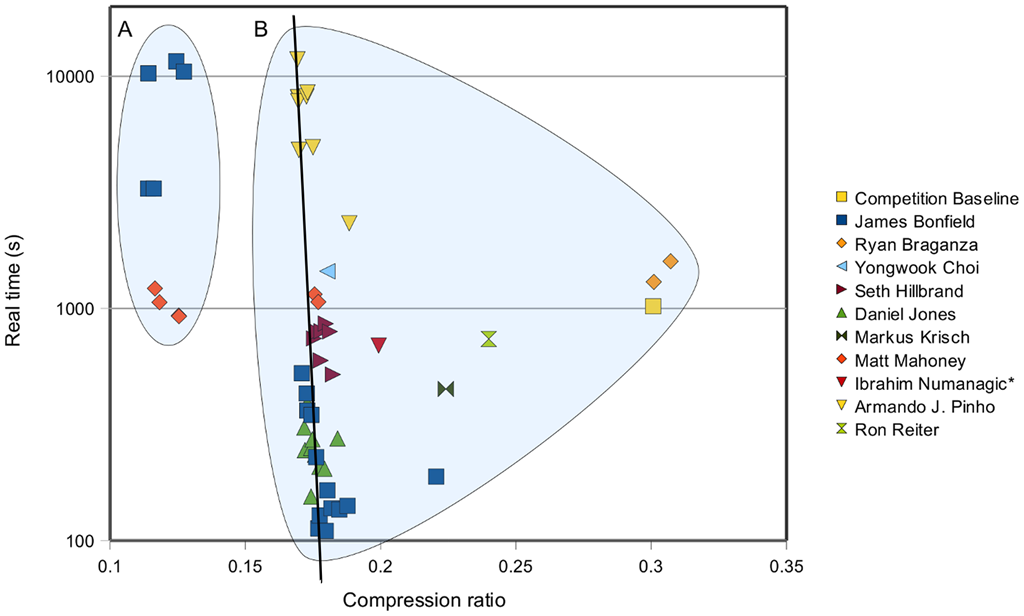
The nearly vertical line there shows a trend - more CPU time for slightly less storage cost. We see this trend a lot. Note that we have a linear X axis and a logarithmic Y axis. Ie it's exponentially more expensive to gain a little more compression ratio. Less extreme examples are visible at the Large Text Compression Benchmark. Presumably less extreme there as more information can be gleaned from text than a FASTQ file (or so we thought at the time).
Modern tools such as Spring completely trounce this line - let's face it I got lucky with the timing - although it is still at the expense of high memory if not quite so much high CPU (it's not cheap though in CPU either), bridging the gap between referenceless (B) and refererence-based (A) compression tools.
So what is the sweet spot? My aim has always been the bottom left, at the base of "the wall". Somewhere close to optimal compression without the burden of high memory or high CPU.
With newer CRAM codecs I aim to push it further and to give people more choice in the way of named profiles (fast, normal, small and archive), but still it's got to be practical to be useful and by default that's where it'll be focused - sufficient compression without sacrificing performance.
CRAM profiles
Profiles in CRAM are purpose driven, but will simply match a whole bunch of command line arguments (much how bwa has profiles for specific types of data). As such they change both the granularity of random access, from 1,000 reads per slice (equivalent to BAM and ideal for lots of random access) to 100,000 per slice (archive). These are also coupled with compression levels and algorithms to be used, so if we are doing lots of random access then we're probably also still reading and writing files lots so are more speed oriented. We can always modify the options after though. Eg "scramble -V3.1 -X normal -s 2000" will use normal compression but at finer granularity.
The "normal" profile is how CRAM works out of the box right now, with larger and smaller variants being available.
I've tried to pick parameters that give meaningful choice, permitting maximum compression still for long term archival, but with "small" mode offering improved compression at reasonable speed. On NovaSeq data this does particularly well without needing to go to the extreme modes. This is in part due to the high degree of binning for quality values meaning there is less to be gained through the FQZcomp codec there:


CRAM 3.1 (I'll probably delay 4.0 until I have some more major format revamping) is still a work in progress, but you can explore the current badly-named branch at https://github.com/jkbonfield/io_lib/tree/CRAM4_updates2 (soon to be merged to master I hope) and track the ongoing work to create the specifation at https://github.com/jkbonfield/hts-specs/tree/CRAMv4 (PDF here although not automatically refreshed with updates).